Spring Cleaning: Replacing Resque with Sidekiq
At Vinted, we have Guilds. No, not the World of Warcraft type - if this was based on computer games, I’d push, oh, so hard for us to have factions (go figure). The Spotify type. At Vinted, a Guild unifies people from different product teams who own and develop a certain area - backend, iOS, analysts, design - to name a few.
Every other thursday we have a Guild day. That’s a whole day dedicated to Guild efforts. People in a Guild conceive their own initiatives, form teams, make a backlog of tasks and work away.
Quite predictably, the iOS Guild will be working on something new and cool, like Vinted for Apple TV, the design Guild might be working on something they call “posh feed”, while we in the backend Guild work mostly on making our life easier via automation of reoccurring tasks and give engineering love to parts of our backend system that no team can reasonably own. Say, the background jobs.
We rely on background jobs for a lot of things - from sending CRM emails and push notifications, to processing transactions. In all our portals combined, we process hundreds of jobs per second under normal circumstances and thousands if we have an intensive CRM campaign going on.
It’s a critical piece of our infrastructure. I was quite surprised when on my first weeks at Vinted I took at look at our Resque admin panel and asked my fellow backenders:
“Why do we have millions of failed jobs in Resque?”
“Oh, nobody ever looks there.”
(Does that sound like a neck of the woods that’s a set for a horror movie?)
Whilst commonly followed logic in this situation might be to split (and either pretend that’s OK if it’s real life, or eventually get killed if it’s a horror movie), but for me it was the moment when I decided I want to join an already ongoing backend Guild effort to replace Resque with Sidekiq.
Ernestas had already laid down the groundwork - hooked up ActiveJob. Myself and Laurynas joined him and together we made a plan for this initiative. Our Trello board looked somewhat like this:
- Figure out what needs to be done with resque-scheduler. Turned out Sidekiq can consume the same schedule yaml file, yay
- Turn on Sidekiq on a sandbox environment and see what happens. We saw that Resque and Sidekiq can run side-by-side (as they use different namespaces in redis), Resque finishing it’s jobs, Sidekiq getting the new ones, yay
- Fix failures (we couldn’t launch it in production with the amount of noise we were having). Most of the failures we had were jobs that tried to process nil records and jobs that were a bit custom, so the general search and replace Resque to ActiveJob did not give the expected result (we have close to 200 different job classes)
- Figure out what’s a comparable amount of Sidekiq processes / threads to our Resque setup. We had quite an overpopulated Resque worker pool (to handle CRM) - about 300 processes. Before we found out Sidekiq offers an Enterprise version (which offers worker pooling), Laurynas had already written a sidekiq-pool gem. We configured pools with different thread counts and hooked it up to our metrics dashboard to see how their’d perform
- Launch on a small number of users and measure average job processing time, to see if Sidekiq is indeed faster than Resque. It is. Sidekiq processed jobs twice as fast as Resque with a little less resources
- Launch everywhere! Keep a few Resque workers to process jobs that are delayed to be run in the future (some tasks, like invoice generation might be already queued to be processed in a month)
- Add monitoring, drop Resque
Surprisingly, we didn’t hit many unexpected issues with this roadmap. We faced problems with mysql connections not being checked in properly. This was the error that kept popping up in Sidekiq failures panel:
ActiveRecord::StatementInvalid: Mysql2::Error: This connection is in use by: #<Thread:0x007f5811657ac8@/.../vendor/bundle/ruby/2.2.0/gems/sidekiq-4.0.2/lib/sidekiq/util.rb:23 dead>
After some research (just being fancy here, after some googling) - we realized ruby timeouts is most likely the culprit. A thread gets a timeout while waiting for a response from mysql and ends up checking a corrupted mysql connection back into the pool.
Another caveat (for us developers dabbling in chef with little oversight of our SRE team) was to learn that it’s not enough to delete the Resque init code from the chef repository and let chef run. The init scripts that are on the servers need to be deleted manually or via chef, but just removing chef recipes does not clean anything up. We found that out the hard way - by running out of memory when our server was trying to run hundreds of resque and sidekiq processes at the same time ☺
When we launched Sidekiq for all our users and fished out most of the errors, we started to think about hooking background jobs into our measurement dashboards. Initially we planned to add only queue backlog counts (that’s what we were measuring for Resque), but after some debates with our SRE team, we concluded that queue latency (how long the oldest job is waiting to be processed) is a great metric for background jobs. Gediminas jumped in and made this possible:
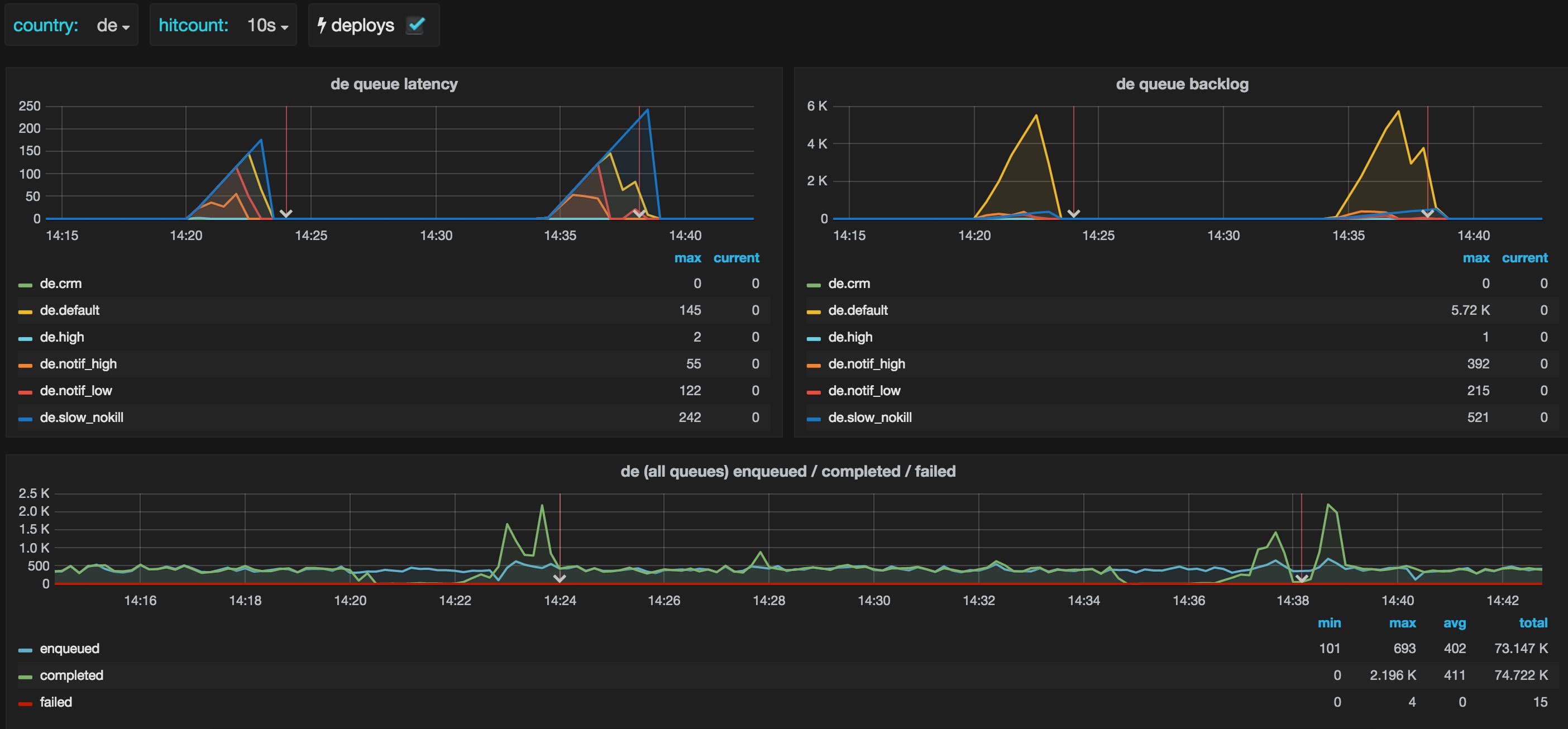 What can be better than a graph that shows you zero’s and that translates to “all’s fine ’n’ dandy”?
What can be better than a graph that shows you zero’s and that translates to “all’s fine ’n’ dandy”?
Here’s the effect the effort has given on our job servers’ CPU and memory. Full switch to Sidekiq happened on week 9:


While Resque might be replaced with Sidekiq, the backend Guild initiative to work on background jobs is not over. Our goal is not to replace one technology with another one, but to get real cash savings for our company. Stay tuned, we’re making a new plan ;)
Thanks to everyone who’s working on this initiative - Ernestas, Laurynas, Gediminas and our SRE folks - Tomas, Nerijus and Paulius.